Building A Hybrid Book Recommender System: Combining Collaborative Filtering With Content-Based Recommendations, Using Web Scraping And Logging
A blog about my journey of building a hybrid book recommender


Table of contents
- In this blog, we delve into the world of book recommender systems, uncovering a powerful solution that combines the strengths of collaborative filtering and content-based recommendations. Harnessing the potential of web scraping and logging for data collection would shed some light on developing a hybrid approach for generating book recommendations.
- Data Collection and Preprocessing: Laying the Foundation
- Collaborative Filtering: A Key Ingredient
In this blog, we delve into the world of book recommender systems, uncovering a powerful solution that combines the strengths of collaborative filtering and content-based recommendations. Harnessing the potential of web scraping and logging for data collection would shed some light on developing a hybrid approach for generating book recommendations.
Data Collection and Preprocessing: Laying the Foundation
Before we delve deeper into the mechanics of collaborative filtering and content-based recommendations, let's start at the very beginning: data collection and preprocessing.
Data Collection:
For our book recommender system project, we needed a substantial amount of data to draw meaningful recommendations. We obtained this data from the Book Crossings dataset, which comprises three essential files:ratings.csv,books.csv, andusers.csv.Data Merging: The next step was to merge these data files to create a unified dataset that contains all the relevant information. Python's Pandas library was a valuable tool in this process. Here's how we combined these files:
import pandas as pd df_ratings = pd.read_csv('ratings.csv') df_books = pd.read_csv('books.csv') df_users = pd.read_csv('users.csv') final_data = pd.merge(pd.merge(df_ratings, df_books, on='isbn'), df_users, on='user')Data Filtering
With a massive dataset in our hands, it was crucial to filter out the noise and focus on meaningful user-book interactions. We accomplished this by setting thresholds for both users and books based on the number of reviews they had. This filtering ensured that we concentrated on popular and active users and books, providing more relevant recommendations.
Here's the code snippet for this data-filtering process:
We essentially filter apply a filter and get those users who have given more than 100 reviews and those books that have more than 10 reviews on them.
here df_ratings is the data frame corresponding to the ratings.csv
user_review_counts = df_ratings['user'].value_counts() popular_users = user_review_counts[user_review_counts > 100].index book_review_counts = df_ratings['isbn'].value_counts() popular_books = book_review_counts[book_review_counts > 10].index filtered_ratings = df_ratings[ (df_ratings['user'].isin(popular_users)) & (df_ratings['isbn'].isin(popular_books)) ]Building the User-Book Interaction Matrix:
Now that we have a refined dataset, we need a structured way to represent user preferences. To achieve this, we created a pivot table where rows represent book titles, columns represent users, and the cell values represent user ratings for each book. This matrix is the foundation for collaborative filtering. Here's how it was done:
table = final_data.pivot_table(index='title', columns='user', values='rating')With our data now appropriately structured, we were ready to explore the world of collaborative filtering and content-based recommendations. But that's a story for the following sections.
Collaborative Filtering: A Key Ingredient
Collaborative filtering is a fundamental technique in the world of recommendation systems. At its core, it leverages the collective wisdom of users to make personalized recommendations. The idea is simple but powerful: if User A shares similar preferences with User B on various items, such as books, movies, or products, then it's likely that the two users will also have similar tastes in other, yet-to-be-discovered items.
Collaborative filtering can be approached in two ways: user-based and item-based. The former focuses on finding users who are similar to the target user, while the latter concentrates on identifying items that are similar to those the user has already expressed interest in.
Cosine Similarity: The Measure of Resemblance
Cosine similarity is a crucial concept when it comes to collaborative filtering. It's a mathematical measure that quantifies the similarity between two vectors in a multi-dimensional space. In our case, each book can be thought of as a vector in a high-dimensional space, where each dimension represents a feature or attribute of the book.
The cosine similarity between two book vectors is calculated by taking the dot product of the vectors and dividing it by the product of their magnitudes. This results in a value between -1 and 1, where 1 indicates that the two vectors are identical, 0 means they are orthogonal (completely dissimilar), and -1 means they are diametrically opposed.
Taking an example of 2d vectors here is how the cosine values are calculated:
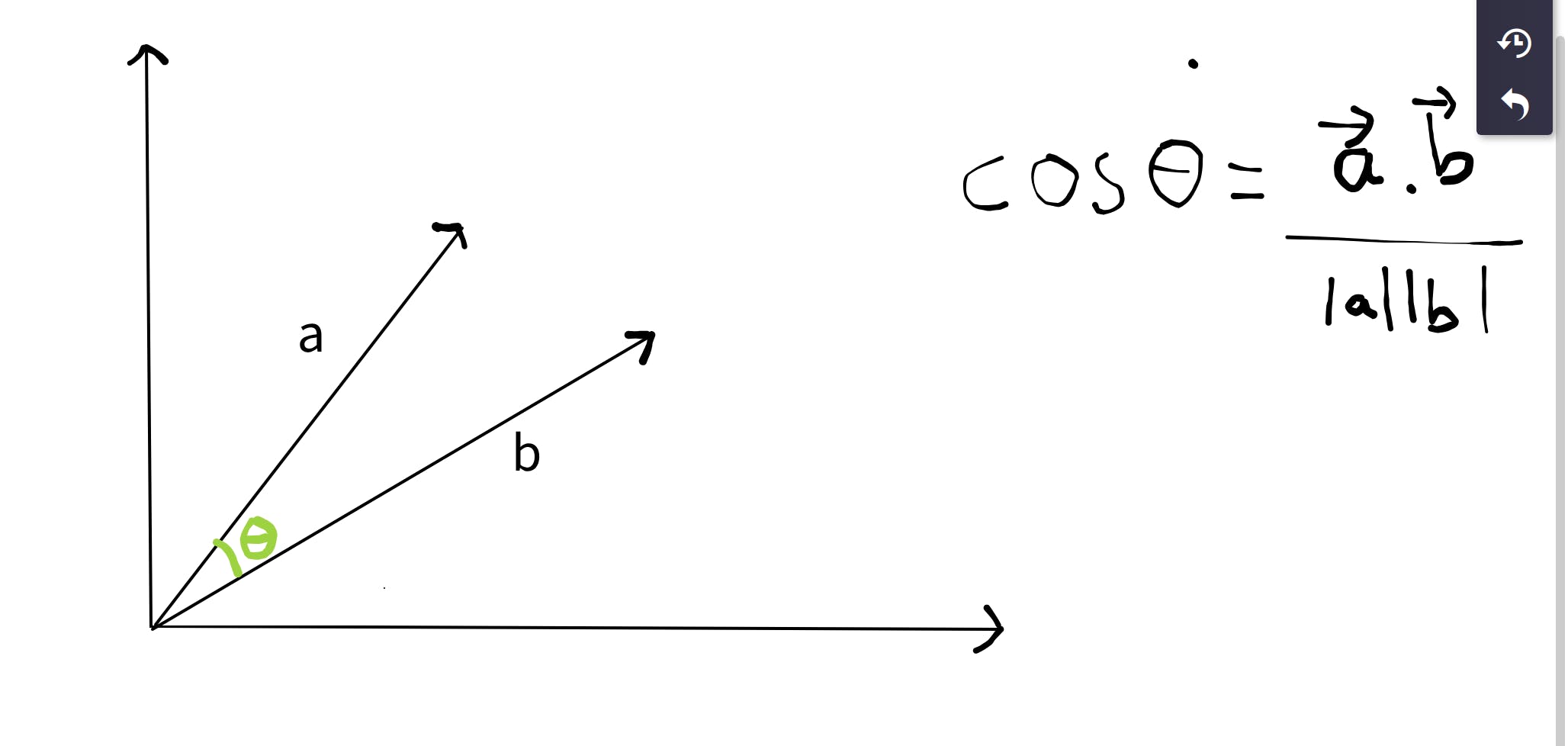
But for our purpose we don't have a 2d plane , we have our users as the features and the vectors of each book would have a component along every user.So if we have n users we would get an n-dimensional plane where each book vector will have a vector whose n components would be the rating of that book by each user.
Mapping Book Vectors: How Cosine Similarity Powers Recommendations
Now, here's where the magic happens. We used cosine similarity to map book vectors in our hybrid book recommender system. When a user expresses interest in a particular book, we first calculate the cosine similarity between the user's preferences (represented as a vector) and the vectors of all other books in our database.
The books with the highest cosine similarity values are considered the most similar to the user's preferences. This information is then used to generate recommendations. In essence, we're finding books that are geometrically closest to the user's taste in this high-dimensional space.
Collaborative filtering, in conjunction with cosine similarity, forms the basis of the collaborative part of our hybrid system. But that's only half of the story. The other half is where content-based recommendations come into play, and we'll dive deeper into that in the next section.
Here is the code to obtain the cosine similarity matrix (using sklearn):
from sklearn.metrics.pairwise import cosine_similarity
cosine_sim_matrix = cosine_similarity(table, table)
| Book 1 | Book 2 | Book 3 | Book 4 | |
| Book 1 | 1 | 0.6 | 0.3 | 0.8 |
| Book 2 | 0.6 | 1 | 0.4 | 0.9 |
| Book 3 | 0.3 | 0.4 | 1 | 0.7 |
| Book 4 | 0.8 | 0.9 | 0.7 | 1 |
This is how our cosine similarity matrix might look like, note the points where values are 1, a book is completely similar(identical) to itself so those entries will always remain one, so this cosine similarity matrix helps us identify the closeness between books and thus for each book the closet books can be recommended.
So for scraping book descriptions, we used BeautifulSoup which is a powerful python library for scraping web pages(especially static ones)
import requests
from bs4 import BeautifulSoup
import os
import time
output_directory = "descriptions"
if not os.path.exists(output_directory):
os.makedirs(output_directory)
- In this section, we set up the
output_directorywhere scraped book descriptions will be saved. We also check if the directory exists and create it if it doesn't.
Next, we have a function for fetching book descriptions:
fetch_book_description(isbn):
url = f"https://openlibrary.org/isbn/{isbn}"
response = requests.get(url)
- The
fetch_book_description(isbn)function takes an ISBN and constructs the URL to OpenLibrary to fetch the book description.
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
description_element = soup.find('div', {'class': 'book-description'})
- This part checks if the web request was successful (status code 200) and parses the HTML content using BeautifulSoup. It then searches for the book description within the HTML using its class.
if description_element:
description = description_element.get_text(strip=True)
return description
If a book description is found, it's extracted and returned.
def descextract(isbn_list): for isbn in isbn_list: description = fetch_book_description(isbn)
- The
descextract(isbn_list)function iterates through a list of ISBNs and uses thefetch_book_description()function to fetch descriptions.
def descextract(isbn_list):
for isbn in isbn_list:
description = fetch_book_description(isbn)
Explanation:
- The
descextract(isbn_list)function iterates through a list of ISBNs and uses thefetch_book_description()function to fetch descriptions.
if description:
filename = f"{isbn}.txt"
with open(os.path.join(output_directory, filename), "w", encoding="utf-8") as file:
file.write(description)
print(f"Saved description for ISBN {isbn} to {filename}")
else:
print(f"Description not found for ISBN {isbn}")
time.sleep(0.7)
print("Done")
- If a description is found, it's saved to a text file with the ISBN as the filename. If not found, a message is printed. There's also a small delay between requests to be considerate to the server.
This completes the explanation for the web scraping part. Now, we'll provide a code snippet for the Doc2Vec-based book vectorization.
What is Doc2Vec?
Doc2Vec is an extension of Word2Vec, a popular word embedding technique used in natural language processing and machine learning. Word2Vec learns vector representations of words based on their context within a large corpus of text. Similarly, Doc2Vec extends this idea to learn vector representations of entire documents, such as paragraphs, sentences, or in your case, book descriptions.
In the context of your book recommender system, each book description is treated as a document, and Doc2Vec is used to learn a vector representation for each description. These vectors capture semantic information about the content of the descriptions, allowing you to measure the similarity between descriptions (and thus, books) based on their vector representations.
Now, let's proceed with the code snippets.
In this section, we'll prepare the data and create a Doc2Vec model.
import os
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
import json
data_dir = "./descriptions"
We start by importing necessary libraries and specifying the directory where the scraped book descriptions are stored.
with open("ind_to_book.json", "r", encoding="utf-8") as json_file: ind_to_book = json.load(json_file)
- We load a JSON file containing information about book indices and titles that will be used later to tag our documents.
Continuing with the code in the next section:
def preprocess_text(text):
tokens = text.lower().split()
return tokens
- Here, we define a function called
preprocess_text()that tokenizes the text by splitting it into words and converting them to lowercase. This preprocessing is necessary to prepare the text for modeling.
documents = []
file_paths = [os.path.join(data_dir, f"{i}.txt") for i in range(13629)]
- We initialize an empty list called
documentsto hold our tagged documents. Thefile_pathslist is created to point to individual book description files.
Next, we continue with model creation and training in the next section:
for file_path in file_paths:
with open(file_path, "r", encoding="utf-8") as file:
description = file.read()
tokens = preprocess_text(description)
tag = os.path.basename(file_path).split(".")[0]
We iterate through each book description file and read its content.
The text is preprocessed using the
preprocess_text()function.We extract a unique tag for each description based on the filename (assuming filenames are consistent with book indices).
book_title = ind_to_book[tag]['title']
tokens.append(book_title)
document = TaggedDocument(words=tokens, tags=[tag])
documents.append(document)
We retrieve the book title from the loaded JSON file using the tag.
The book title is added to the list of tokens to ensure it's considered in the model.
A TaggedDocument object is created, associating the tokens (words in the description) with the tag (book index), and then added to the
documentslist.
The code provided here prepares the data and creates tagged documents for the Doc2Vec model.
Initializing the Doc2Vec Model:
Here, we create a Doc2Vec model with specific configurations:
model = Doc2Vec(vector_size=100, window=5, min_count=1, workers=4, epochs=24)
vector_size: This parameter determines the size of the vector representations (embeddings) for the book descriptions. In this case, we've set it to 100, meaning each description will be represented as a 100-dimensional vector.window: Thewindowparameter defines the maximum distance between the current and predicted words when training the model. In a document context, it's the maximum number of words before and after the current word that the model considers. A value of 5 indicates a relatively small context window.min_count: This parameter sets a threshold for the minimum number of times a word or phrase must appear in the corpus to be included in the vocabulary. By setting it to 1, we're including all words that appear at least once.workers: Theworkersparameter specifies how many CPU cores to use during model training. Using multiple workers can significantly speed up the training process. Here, we've set it to 4.epochs: Theepochsparameter defines the number of iterations (passes) over the dataset during training. In this case, the model will be trained for 24 epochs.
Building the Vocabulary:
model.build_vocab(documents)
- The
build_vocab()method prepares the model's vocabulary based on the tagged documents (in our case, the book descriptions). It scans the documents, assigns unique integer IDs to words, and creates a vocabulary for training the model.
Training the Doc2Vec Model:
model.train(documents, total_examples=model.corpus_count, epochs=model.epochs)
- The
train()method is used to train the model on the tagged documents. We provide thedocumentsas the training data, specifytotal_examplesas the number of documents in the corpus (in this case, it's the same as thecorpus_countof the model), and indicate the number of trainingepochs(24 in this example).
Now that we've explained the initialization, vocabulary building, trainingsteps of the Doc2Vec model, let's proceed with creating book vectors and calculating cosine similarity, which will be used for recommendations.
pythonCopy codebook_vectors = [model.dv[f"{i}"] for i in range(13629)]
- This code snippet extracts the vector representations (embeddings) for each book description using the trained Doc2Vec model. The
model.dv[f"{i}"]syntax retrieves the vector for the i-th book description.
cosine_mat = cosine_similarity(book_vectors, book_vectors)
- Finally, the
cosine_similarityfunction is used to calculate the cosine similarity between book vectors, resulting in a matrix (cosine_mat) where each element represents the cosine similarity between two books.
These similarity scores can then be used for recommending books to users based on their preferences. The higher the cosine similarity, the more similar two book descriptions are, indicating that users who liked one book might also like the other.
Merging both approaches:
Now that we have obtained similarity matrices that represent two different aspects of book recommedations , we can merge them and take a weighted average and create a new unified matrix for book recommendations:
import numpy as np
cosine_sim_matrix_user = np.array(cosine_sim_matrix)
cosine_sim_matrix_description = np.array(cosine_mat)
weight_user_reviews = 0.7
weight_book_description = 0.3
combined_cosine_sim_matrix = (weight_user_reviews * cosine_sim_matrix_user) + (weight_book_description * cosine_sim_matrix_description)
Conclusion: Navigating the World of Python and Machine Learning
Throughout this project, we(I along with my team members for this project) embarked on a captivating exploration, delving into the realms of data collection, web scraping, and the construction of a hybrid book recommender system.
Starting with the foundational element of data, we ventured into the Book Crossings dataset, highlighting the significance of quality data as the bedrock of machine learning projects. The project required us to grasp web scraping and data preprocessing techniques, crucial for the extraction of meaningful insights from our dataset.
Our journey led us to two key recommendation strategies: collaborative filtering, which leverages the wisdom of fellow users, and content-based recommendations, which rely on detailed book descriptions to match users with their literary preferences. At the heart of these strategies was the remarkable concept of cosine similarity, a mathematical measure that allowed us to calculate the resemblance between users and books, as well as between books themselves.
Simultaneously, we addressed the task of gathering comprehensive book descriptions through web scraping on OpenLibrary. The trove of data was then harnessed to generate vector representations via the powerful Doc2Vec model, enriching our understanding of the textual content within each book description.
As we traversed the final leg of our journey, we reached a significant milestone in our recommender system—the calculation of cosine similarities among book vectors. This laid the groundwork for a robust recommendation system capable of guiding readers toward their next captivating literary journey.
The amalgamation of programming skills, web scraping, machine learning, and my unwavering love for books has culminated in a potent book recommender system. This project is merely a snapshot of my exciting path of exploration and discovery.
So, onward and upward! Let's keep exploring, keep learning, and keep innovating. The journey is an exhilarating one, and the world of Python and machine learning is vast and inviting. It's an exciting road ahead, and I'm looking forward to every step of it.